Marcinie,
I ćwiczymy zatem na danych zgromadzonych w tabeli wysylka_1
Dla tych co by też chcieli, a nie wiedzą o co chodzi to
polecam zajrzeć pod linkę:
Na początek prosta kwestia:
- podaj podstawowe informacje o zebranych danych,
ale już agregowane ze względu na datę wysyłki, płeć odbiorcy, województwo
odbiorcy,
- podaj średni czas odpowiedzi, najszybszy czas
reakcji, najdłuższy czas reakcji,
- podaj ilu ludzi nie zareagowała i ilu
zareagowało na naszą wysyłkę.
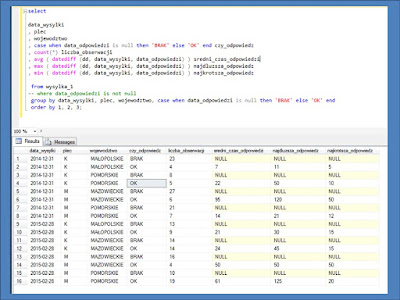
Wszystkie odpowiedzi są do uzyskania zaprezentowaną na
rysunku kwerendą.
1 – W zasadzie tu nie musi być, bo musi tak naprawdę w
sekcji po GROUP BY, ale tu też bardzo często występuje, bo podzielenie zbioru,
wyliczenie wartości, a później brak informacji kogo dotyczy informacja… nieco
bez sensu.
A dlaczego? Bo zbiór
wszystkich 200 wierszy podzielimy na podzbiory/grup według województwa, daty
wysyłki, płci, na tym polega grupowanie. To tak jak w szkole, przecież mamy
uczniów, oni są podzieleni na klasy i dopiero wówczas się liczy średnią ocen,
grupowanie nastąpiło dawno temu, nawet nie pamiętamy kiedy J To bardzo częste w
życiu, na co nie zwracamy nawet uwagi, jest to naturalne. Pracując z danymi musimy
to czynić jawnie, komputer nie czyta nam w myślach.
2 – To samo co wyżej oraz użyłem klauzulę CASE, przy jej
pomocy określam wartość w dodatkowym polu, to dodatkowe pole (kolumna) będzie
się nazywać CZY_ODPOWIEDZ, będzie
zawierać wartości dwie, BRAK lub OK. To według tych etykiet też podzielmy nasz
zbiór danych, to też skopiuję do sekcji po GROUP BY.
3 – Ta sekcja, to miejsce gdzie liczymy / podajemy jakie
wartości dla każdego podzbioru określimy, a zatem policzymy ile wierszy w
podzbiorze jest, policzymy średni czas odpowiedzi w podzbiorze, najdłuższą
odpowiedź, najkrótszą odpowiedź. Tu zwracam uwagę na nowinkę, jeżeli chcemy
uzyskać liczbę dni pomiędzy dwoma datami to musimy wykorzystać funkcję DATEDIFF
(… , data1, data2). Jeżeli w miejscu kropek podamy dd, to uzyskamy liczbę dni
pomiędzy datami, mm – to liczba miesięcy, a yy – to liczba lat.
4 – Na początku tego wiersza są dwa myślniki, taki sposób
zapisu powoduje, że wiersz jest traktowany jako komentarz do kwerendy, zatem
zostanie pominięty przy wykonywaniu kwerendy, odkomentowanie, tj. usunięcie
tych myślników, spowoduje że zostanie wiersz
odczytany, zostaną zgodnie z treścią pominięte z wyniku zapytania wiersze
niemające wypełnionego pola DATA_ODPOWIEDZI.
5 – tu musisz wiedzieć, że gdy pomiędzy SELECT a WHERE
chcesz uzyskać wartości agregowane, np. liczby wierzy, średnie …. To musisz
podpowiedzieć bazie jak ma podzielić zbiór, tu podajesz po GROUP BY, które pola
są dla ciebie ważne, według nich podzielony zbiór. Tu bardzo często musisz po
prostu zawrzeć to samo co jest pomiędzy SELECT a WHERE, a nie jest agregowanym
polem. Dlaczego takie powtarzanie jest konieczne, ano dlatego że tak naprawdę
nie musisz pomiędzy SELECT a WHRERE wyświetlać wartości np. pola
„DATA_WYSYLKI”, a pogrupować możesz chcieć, co prawda nieczytelny staje się wynik,
ale tak można, nie ma obowiązku powtarzania treści.
I co widać, jak wykonasz kwerendę :-)
Zobacz czy to samo co mnie, jak masz pytania to daj znać.
I kwerenda byś nie musiał przepisywać:
select
data_wysylki
, plec
, wojewodztwo
, case when data_odpowiedzi is null then 'BRAK' else 'OK' end czy_odpowiedz
, count(*) liczba_obserwacji
, avg ( datediff (dd, data_wysylki, data_odpowiedzi) ) sredni_czas_odpowiedzi
, max ( datediff (dd, data_wysylki, data_odpowiedzi) ) najdluzsza_odpowiedz
, min ( datediff (dd, data_wysylki, data_odpowiedzi) ) najkrotsza_odpowiedz
from wysylka_1
-- where data_odpowiedzi is not null
group by data_wysylki, plec, wojewodztwo, case when data_odpowiedzi is null then 'BRAK' else 'OK' end
order by 1, 2, 3;